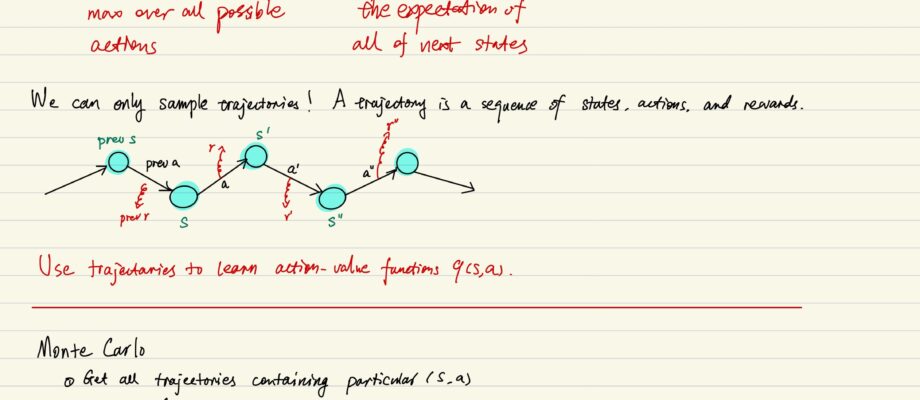
Model-free Reinforcement Learning
Value Iteration in real world n real world, we don’t have the state transition probability distribution or the reward function. You may try sampling them, but you will never know the exact probabilities of them. As the result, you can not compute the expectation of the action values. We want a new algorithm that would … Continue reading Model-free Reinforcement Learning
0 Comments