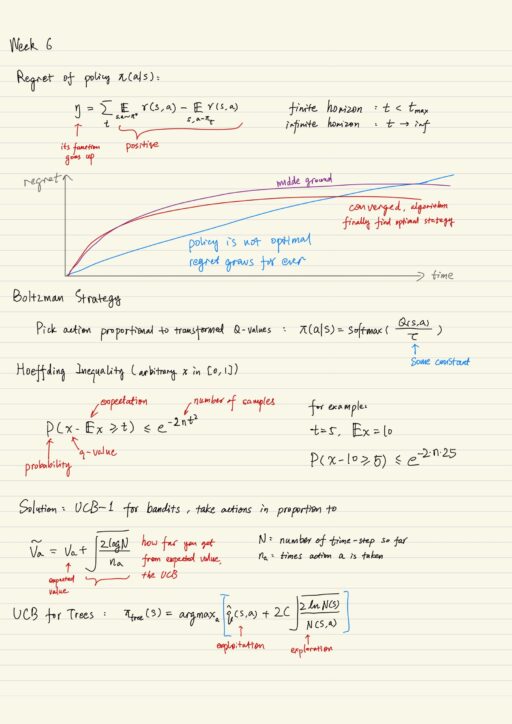
Practical Reinforcement LearningHigher School of Economics I am very proud that I survived and completed this thorny but exciting journey with Honors. I spent nearly 1 month on this very challenging course, which covers enormous amount of knowledge. The lecture videos are all well-prepared, they not only help me consolidate my original understanding, but also…