
Deep Q-Network (DQN) is the first successful application of learning, both directly from raw visual inputs as humans do and in a wide variety of environments. It contains deep convolutional network without hand-designed features. DQN is actually no more than standard Q-learning bundled with stability and epsilon-greedy exploration.
In any application, the first thing you shall do is to reduce the complexity of the task. For reinforcement learning, it means reducing the space of states as much as possible. In the context of Atari game, the reducing process consists of 3 parts: gray-scaling, downsampling and cropping. Pooling is not in this architecture. Because it does not have any parameters but requires additional computation time. Stride convolutions could replace it with more-or-less effect on the modeling power.
The reason why we have 4-frame stack is decision based solely on one image is not optimal. Because no one can infer the direction and speed. This lack of comprehensive information in an observation is “partial observability”. An environment with incomplete information in an observation is “partially observable Markov Decision Process” (POMDP). Stacking 4 images (frames) in a row completely remove s partial observability. This works well for velocity, acceleration and various things. For some tasks it may turn POMDP into MDP, greatly reducing the difficulty of the task.
Problems solved
DQN fixed some of the instability problems:
- Sequential correlated data. Fixed by using Experience Replay.
- Instability of data distribution due to policy change. Fixed by using Target networks.
- Unstable gradients. Fixed by using Reward Clipping.
Why does Experience Replay help? If the pool is large enough, we effectively de-correlate the data by taking different pieces of different trajectories. It improves learning stability, increase sample efficiency. But it only works with off-policy algorithms, it is memory intensive.
Experience Replay partially solved the second problem (policy oscillation). “Targets” still depend on the “network parameters”. Error made in any target immediately propagates to other estimates. How can we break the ties between “targets” and “network parameters”? Let us just split parameters of q-values of targets from parameters of current learning q-values approximation. Now we have two different networks: target network and q-network. Now it is crucial to update parameters between parameters of 2 networks.
Reward Clipping clips reward to [-1, 1], but it can not distinguish between good and great. This method was not adopted by further researchers.

Expectation of Maximum VS. Maximum of Expectation
First each possible action of next state s’ can be stochastic due to a number of causes. So each action will yield action values whose range varies over time. The network will have some approximation error and there are some perturbations in q-value of Q(s’, a) due to gradient descent between iterations. Once we actually apply the formula we use for Q-learning, we get some unintended effects.
The unintended effect is you usually won’t get the maximum of expectations of Q-values, you get the maximum of sample q-values. Suppose all actions have expectations equal to 10, then the maximum of these expectations shall also equal to 10. But now you pick up maximum of samples, which is likely to be greater than 10. Then the expectation of maximum of sample q-values will be greater than 10. The conclusion is you usually get the expectation of maximum (of sample q-values) will be greater than the maximum over expectations.
So if you use samples, you will get something larger than what you actually want. Then the network will be overoptimistic being in some states due to this statistical error. As a result, Q-value will be larger and larger sometimes and never get back.
Double Q-Learning
Double Q-learning fixes the problem of optimism. Simply put, if you can not trust single Q-function, then train two. Those two are independent estimates of the action value functions. In the context of Deep Q-network, there are 2 neural networks that have separate sets of weights (parameters). You update them the one after the other. You use one Q-function to train the other one, and vice versa. Say there are 2 Q-functions, Q1 and Q2 are de-correlated. the noise in Q1 are independent of that in Q2. Then overoptimism disappears.
A good idea is to use Target Network instead of Q2. So you only train Q1, you just take the action value of Target Network (usually the old moving average of Q-values in the past) whose action corresponds to an action optimal on Q1 (the current Q-network).

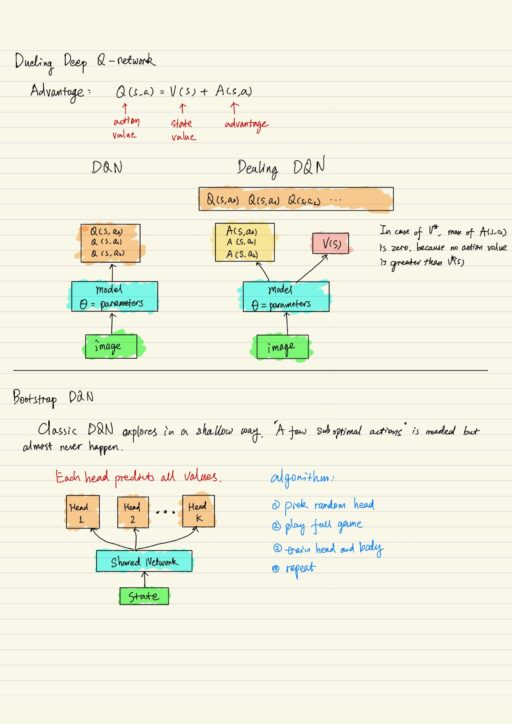
Dueling Deep Q-Network
QDN is trying to approximate a set of values that are very interrelated. When any of actions won’t change much, all actions will have similar values in current situation, because even a wrong action won’t hurt. There are also situations where action values differ a lot, these are the cases where one action can make it or break it.
Advantage is how much action value differs from the state value: A(s,a) = Q(s,a) – V(s). In classic DQN, we use neural network to predict q-values independently via dense layer. With the decomposition of advantage, we can modify classic DQN into Dueling DQN. In Dueling DQN, you actually train V(s) and A(s, a), then you just add them up to get action values Q(s, a).
Bootstrap DQN (Deep Exploration Policy)
Classic DQN explores in a shallow way. If use epsilon greedy, the problem is the probability of taking a few sub-optimal actions will almost be zero. Bootstrap DQN solves the problem to give suboptimal actions more chance – make exploration great again! In Bootstrap DQN, you have to train a set of value predictors (head), which share the same convolutional layers (body). The way the are trained is at the begin of every episode, you pick a head. Then you follow its actions and train the weights of head and body.
My Certificate
For more on Deep Q-Network in Reinforcement Learning, please refer to the wonderful course here https://www.coursera.org/learn/practical-rl
Related Quick Recap
I am Kesler Zhu, thank you for visiting. Check out all of my course reviews at https://KZHU.ai