Non-personalized recommenders systems are remarkably effective tools and still useful in various situations. For example: recommendation in print for restaurants. Sometimes we know a little about users: age, gender, zip code. We can do a little week personalization. Also product associations allow recommendations based on current page, item, or context.
Summary Statistics
This is a technique used for non-personalized recommendation. A score is usually used, and when computing the score, we need to make sure “What does score mean?” and “How to compute them?” The score can mean popularity, average rating or the probability of you liking it. We can use frequency, average or more complicated method to compute. The scores may be affect by self-selection bias, and increased diversity of raters. And they have a few drawbacks:
- Popularity is an important metrics
- Average can be misleading
- More data is better until you overwhelm people
This technique also missed a few elements: “Who are you?” and “the context you are in”. Many of the limitations of non-personalized summary statistics can be solved by ephemeral and persistent personalization.
The purpose of predicting and showing aggregated preference is to help user decide whether to buy, read, or whatever. A few simple display approaches include:
- average rating
- upvote proportion
- number of likes (upvotes)
- percentage of positive feedback
- full distribution
You usually do not have to rank items by aggregated preference scores, but consider these:
- Confidence – how much do you confident that it is a good item?
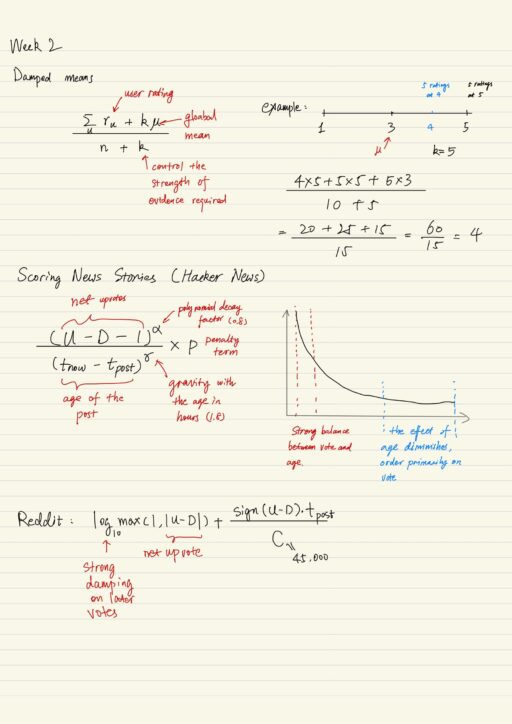
- When there is few ratings, we have no confidence to recommend. We can assume that without confidence, everything is average, and each rating is a piece of evidence that this item is not average. As we get more and more ratings, the k initial global mean ratings diminish.
- Risk tolerance – is it high-risk, high-reward or conservative?
- The choice of bounds affect the risk and confidence. The lower bound is conservative, being sure it is good. The upper bound is risky, there is a chance to be amazing. This interval narrows as you get more and more evidence.
- Domain and business consideration – time, age, system goals.
- Take “age of post” as example: as the post getting older, initially a post’s rank drops quickly, when the post gets older, the effect of its age diminishes.
Demographics
The idea is to label people with some attributes to do a better job making better recommendations. We start by identifying what demographic or correlates we have, then we explore where your data correlates with demographics by using scatterplot. If you find some relevant demographics, then:
- Break down “summary statistics” by demographics
- Build a multiple regression model, which can predict based on demographic statistics.
- linear regression for multi-valued data (eg. ratings)
- logistic regression for true/false data (eg. purchase or not)
You need defaults for unknown demographics. If demographics are useful, getting user data is the key. In many cases, demographics work as products and contents are created to reach them. But it fails miserably for people whose tastes do not match their demographics.
Product Association Recommendation
Product association recommenders uses present context to provide more relevant recommendations. This is actually ephemeral contextual personalization, which is tied to “what you are doing right now”, and can be computed from transaction history. It might be targeted as additional purchase or replacement, and is done in 2 ways:
- Manual cross-sale tables
- Data mining associations
In fact not all recommendations are worth making, product association is just like any other recommendation. Businesses tend to apply rules to filter what they recommend. For example do not recommend products out of stock or with big discount. Not every recommendation makes sense.
My Certificate
For more on non-personalized recommenders, please refer to the wonderful course here https://www.coursera.org/learn/recommender-systems-introduction
Related Quick Recap
I am Kesler Zhu, thank you for visiting my website. Checkout more course reviews at https://KZHU.ai


